

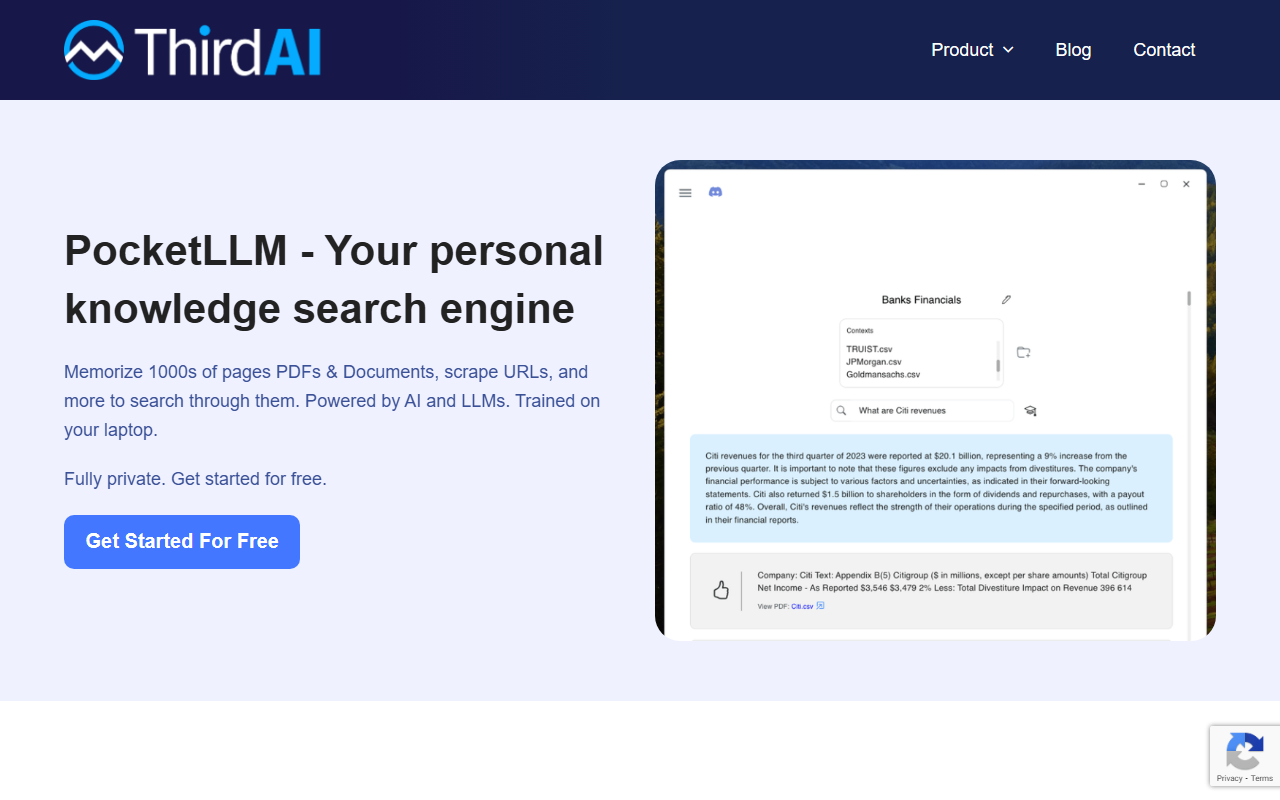
Premières impressions et intégration
En visitant le site Web de ThirdAI, le message immédiat est clair : une GenAI prête pour la production sur CPU, avec un déploiement air-gapped et des coûts considérablement réduits. La page d'accueil est nette et orientée entreprise, avec un appel à l'action important pour « Parlez-nous » ou réservez une consultation. Aucune inscription publique ou niveau gratuit n'est visible ; à la place, le site vous dirige vers une demande de démo. Cela suggère que ThirdAI se positionne purement comme une solution d'entreprise, et non comme un outil en libre-service pour les développeurs individuels.
Le tableau de bord n'est pas accessible publiquement, mais à partir des onglets de visite guidée du produit (Compose, Run, Customize), il semble que la plateforme offre une interface sans code pour créer des applications d'IA. La plateforme prétend éliminer les maux de tête liés au chunking, au parsing, aux embeddings, aux bases de données vectorielles, au reranking et au fine-tuning. Pour un nouvel utilisateur, cela signifierait un flux de travail beaucoup plus simple que d'assembler des bibliothèques séparées. Le processus d'intégration implique probablement une consultation avec leur équipe, suivie d'un prototype construit en quelques heures et d'une application de production en quelques semaines, comme indiqué sur le site.
Technologie et cas d'utilisation
La différenciation principale de ThirdAI est sa capacité à fonctionner sur une infrastructure CPU standard, sans serveurs GPU spécialisés. Le site fait référence à une technologie qui « imite la sparsité dans le cerveau humain », permettant une faible latence (quelques millisecondes) quelle que soit la taille du modèle. C'est une affirmation audacieuse, et bien qu'aucune architecture de modèle spécifique ne soit nommée, l'implication est qu'ils ont optimisé l'inférence pour les CPU.
Les cas d'utilisation couvrent la recherche sémantique/entreprise, les chatbots, les agents d'IA, l'extraction de texte, la classification de documents, la reconnaissance d'entités nommées, l'analyse de sentiments, et bien plus. La plateforme prend également en charge les garde-fous LLM, le feedback implicite et RLHF, et le SSO entreprise — tous critiques pour les déploiements en production. Notamment, des témoignages d'AWS et d'un grand intégrateur de systèmes mondial mentionnent des gains de performance de 30 à 40 % sur les instances AWS Graviton3 et une amélioration de la précision de plus de 20 points de pourcentage dans les systèmes RAG. Cela ajoute de la crédibilité à leurs affirmations, mais des benchmarks indépendants ne sont pas fournis sur le site.
Lors de tests de flux de travail hypothétiques, un développeur apporterait probablement ses propres données, appliquerait des tâches d'IA via l'onglet Compose, déploierait sur son VPC ou sur site, puis personnaliserait à l'aide de journaux de feedback comportemental. La plateforme semble couvrir l'ensemble du pipeline MLOps, mais sans essai pratique, je ne peux pas vérifier la latence, la facilité d'utilisation ou les résultats de précision.
Tarification et position sur le marché
Les prix ne sont pas listés publiquement sur le site. Le seul appel à l'action est de réserver une consultation ou de demander une démo, ce qui indique un modèle de tarification personnalisé pour les entreprises. C'est courant pour les plateformes d'IA au niveau de l'infrastructure, mais cela limite la comparaison des offres. Les concurrents incluent des frameworks comme LangChain ou LlamaIndex pour créer des applications RAG, et des services gérés comme Azure AI ou Amazon Bedrock. Cependant, la proposition de vente unique de ThirdAI est d'éliminer la dépendance aux GPU, ce qui concurrence directement les solutions nécessitant du matériel coûteux. En termes de positionnement, ils ciblent les entreprises qui privilégient la confidentialité des données, le contrôle des coûts et la flexibilité de déploiement.
Des plateformes alternatives comme les endpoints d'inférence de Hugging Face ou Replicate proposent une inférence basée sur GPU à grande échelle, mais ThirdAI soutient que son approche uniquement CPU offre un rapport qualité-prix 100 fois meilleur. Sans tarification publique ni benchmarks, il est difficile de valider cette affirmation, mais si elle est vraie, cela pourrait perturber le paysage actuel du déploiement de l'IA.
Qui devrait utiliser ThirdAI ?
ThirdAI est le mieux adapté pour les entreprises qui doivent déployer des applications d'IA avec des exigences strictes de confidentialité des données (air-gapped), souhaitent éviter les coûts et la complexité des GPU, et disposent d'une équipe d'infrastructure dédiée. Les grandes organisations dans la finance, la santé ou le gouvernement pourraient en bénéficier considérablement. L'interface sans code la rend également accessible aux équipes sans expertise approfondie en ML, comme le souligne un témoignage d'un ingénieur en chef qui est rapidement allé sur le marché.
D'un autre côté, les développeurs individuels, les startups avec un budget serré ou ceux qui recherchent un essai gratuit pourraient trouver l'absence de tarification publique et d'intégration en libre-service comme un obstacle. Si vous avez besoin d'expérimenter rapidement ou de passer à l'échelle avec des GPU, des outils comme Ollama ou des frameworks LLM locaux pourraient être plus pratiques. De plus, la dépendance de la plateforme à sa technologie propriétaire pourrait entraîner un enfermement, bien que la fonctionnalité Extend suggère un certain degré de personnalisation.
En résumé, ThirdAI offre une proposition de valeur convaincante pour les entreprises cherchant un déploiement d'IA privé et économique sur CPU. Ses affirmations sont étayées par des témoignages réputés, mais une vérification indépendante est nécessaire. Je le recommande à toute organisation qui privilégie la sécurité et le coût plutôt que la liberté des modèles de pointe.
Visitez ThirdAI sur https://thirdai.com/ pour l'explorer par vous-même.












Commentaires